


HTTP stands for Hypertext Transfer Protocol — a standard set of rules defining how information systems communicate over the web.
How does it work?
Imagine your favourite restaurant. The job of the chef is to take requests from customers and provide the food requested. In the same way, a web server provides web contents/files to a HTTP client when requested.
Together, the client and the server make up the basic components of the web.
The most common type of client is the browser. When you enter a web address, it makes requests to the server. The client then receives an HTTP response from the server and, if successful, displays information to the screen.
However, to better understand how this works, we need to go over certain concepts.
What are resources?
Much like a kitchen holds food and various culinary equipments, web servers hold resources. A resource is anything important enough to have its own identity (to be uniquely identifiable) on the server. They could be anything — text files, html, word documents, JPEGs or even software programs that generate content based on other data.
So how do I request a resource?
An HTTP transaction involves the client making a request command to the server, and receiving a response result back from the server. Both the client and server communicate with clear blocks of data called HTTP messages.
HTTP messages are in plain text for us to read. Thye consist of three parts:
A start line: Telling you what to do in a request, or what occurred in a response.
The header fields: Simple name-value pairs containing additional information passed on in your request and response.
Body: An optional field that acts as a backpack, carrying data to the client to the server(in a request) or from the server to the client (in a response)
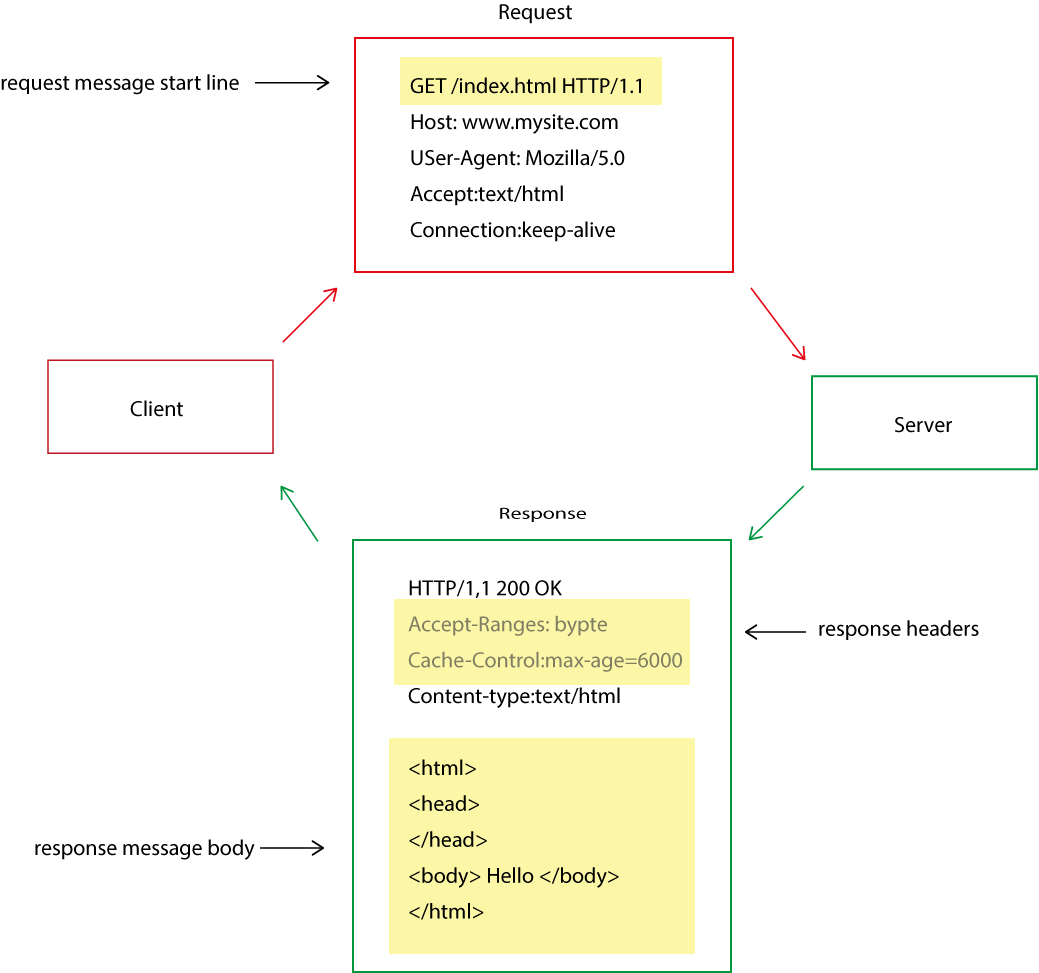 A reductive model of http messages
A reductive model of http messages
It is worth noting that an application could make multiple HTTP transactions to complete a task. For example, a web page may be a collection of resources, not just one. The browser may “fetch” the bare-bones html needed from the page from one server and make extra “fetches” to retrieve other resources, like images, from another server.
How do we send data over the internet?
To understand how data is sent, we look to TCP/IP.
HTTP protocol is layered on top of TCP and uses it to transport data. Before sending a message, a TCP/IP connection is established between the client and server using the servers IP address and port numbers.
The IP Address is the address system of the internet and is responsible for delivering packets of information from one device to another. TCP provides error-free data transfer and ensures that data arrives in the order that it is sent. Once a TCP connection is made, the messages between clients and servers will not be lost or received out of order.
How does the browser identify the different resources on the server?
The web server resources have names. The resource name is called a URI(Uniform resource identifier) — a unique string of characters that act as an identifier. Think of it like a person’s name — John Doe. There are two main types of URI — URL and URN
URL (Uniform Resource Locator)
To locate a resource, you need a URL. This is a type of resource identity that describes the specific location of a resource.
Consider the following URL: [http://www.redfoxjones.com/images/rick-astley.](http://www.redfoxjones.com/images/rick-astley.)URLs are made of three parts.
The scheme — the protocol used to access the resource:
http://The server internet address — the network host name:
[www.redfoxjones.com](redfoxjones.com)A document path naming the resource on the server:
/images/rick-astley
URNs (Uniform Resource Name)
The URN is the a unique identifier of a resource that is independent of where it resides. It does not specify how to locate the resource. The syntax of a URN follows the following format: urn:[namespace identifier]:[namespace specific string]
Note: All URLs are URIs, and all URNs are URIs, but not all URIs are URLs.
The IP address and port number is typically retrieved from the URL. For example in http://203.205.65.43:80/index.html, the IP address is 203.205.65.43 and the port number is 80 . Most times, the IP adresss is not a number, but a hostname — a more readable alternative that makes life a lot easier! For example www.google.com . In this case, we use a Domain Name Service (an address book, if you like), to find the IP addresses of the server. Below is an example of how a DNS look up works.
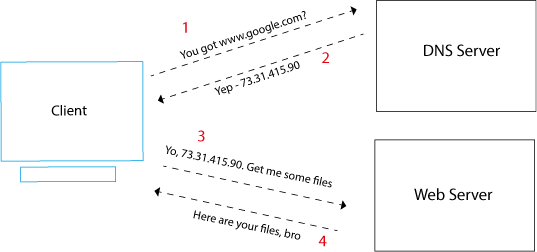 DNS
DNS
But how does the browser figure out what to do with the retrieved data?
The internet hosts different types of data types. To differentiate between them, HTTP tags each one with a label called a MIME (Multipurpose Internet Mail Extension) type.
A MIME type really is a textual label made up of 2 parts: A primary typeand a subtype, separated by a slash. Type refers to similar grouping of data. For example, an HTML text document and an ASCII text document would both have the “type” of “text”. A GIF and a JPEG would both be images. The subtype tag refers to specific types within the grouping. For example gifand jpeg.
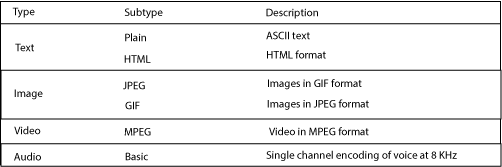 An example of MIME types
An example of MIME types
When a browser receives a resource from the server, it looks at the MIME type to figure out what it is, and what to do with it. This is similar to Microsoft Windows looking at the ‘.docx’ extension and figuring out the file should be opened with Word. The browser then determines the correct plugin to use to allow you to consume the content. For example, playing audio through the computer speakers.
Specifying operations with HTTP Methods
Just like you can give multiple requests to a waiter (For example, make an order, make a change to my order, cancel my order), you can have different requests to the server. The methodtells the server what action to perform.
Here are a few examples:
GET - Send named resource from the server to the client
POST/PUT - Replace/create resource on server
DELETE - Delete resource from server
HEAD - Send only the HTTP headers from the response for the resource
HTTP Status Codes
Every HTTP response message comes back with a status code. Just like a waiter comes back with some information on your order. The status code is 3 digits log and tells the client if the request was successful or otherwise.
Each status code falls in one of 5 categories
[1XX] —
Information responses[2XX] —
Success responses[3XX] —
Redirection messages[4XX] —
Client error responses[5XX] —
Server error responses
For more information, visit the mozilla page
Components of the web
Proxies
A proxy sits between the client and the server. It receives all the clients requests and relays the requests to the server. In our restaurant analogy, the proxy is the waiter, accessing the kitchen on the customer’s behalf.
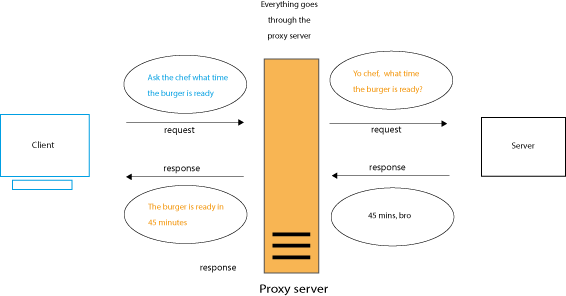 a proxy server
a proxy server
Proxies are typically used for security reasons, acting as an intermediary through which all traffic flows. To consider why this is, imagine if everyone could have access to a restaurant’s kitchen! Proxies may alter and filter requests and responses.
Tunnels
Tunnels are HTTP applications that relay data between two connections. HTTP tunnelling is typically used to bypass firewalls and network restrictions. A popular example is carrying SSL (Secure Socket Layer) traffic through a corporate firewall that only allows web traffic.
Caches.
We also have caches. A cache is a type of web server that keeps copies of frequently requested data. This means there is no need to constantly hit the server asking for the same information. Using our restaurant analogy, imagine if the waiter had to back room each time you requested a menu. Instead, they constantly have it on hand, ready for whoever requests one. It is a good way to better the performance of your web application, by reducing the amount of traffic to the server.
Agents
A User agent is any application that makes HTTP requests on behalf of the user. The browser is an example. A web crawler is an example of this. It scours the web indexing the contents of the web across the internet.
Gateway
A gateway, like a proxy acts as an intermediary for other servers. They are often used to convert HTTP to a different type of protocol. Most times, the client is unaware it is communicating with a gateway. It receives a request as though it was the server containing the resource.
For example, a client might request a file using HTTP protocol, however the gateway may use a File Transfer Protocol to fetch the data from the server.
I hope this article provided a simple and gentle introduction to HTTP.
The next article will dive a little deeper and focus on Basic Authentication. Hopefully it’s a good read!